PDF for Project Proposal
PDF for Project Milestone Report
PDF for Project Final Report
Final Project Slides
⚙ Summary
Our objective is to discover and exploit opportunities for parallelism in Recurrent Neural Networks' (RNNs') inference-time forward pass computations. We aim to effectively utilize synchronization and atomic operations to mitigate the purely-sequential nature to which the data dependencies within and across neural network layers lend themselves, so that we can use parallel computation APIs (e.g. openMP) and vectorized operations on GPUs for multiprocessor speedup.
⚙ Background
We are interested in finding effective ways to obtain speedup on the following basic algorithmic structure of a forward-pass computation in RNNs :
// x is a vector of inputs
a[t] = b + W * h[t-1] + U * x[t]
h[t] = tanh(a[t])
o[t] = c + V * h[t]
y[t] = softmax(o[t])
where the following variables correspond to layers that are vectors of neurons, indexed by time and ordered by increasing proximity to the output layer, y: a, h, o.
We plan to find some ways to mitigate the constraints enforced by dependent data: for example, the constraint on a[t] is the completion of the computation for the hidden layer's h's) output at time t-1. If different threads were responsible for the forward-pass computations of adjacent time steps, there would need to communication of hidden-layer values that would inhibit speedup. We elaborate more on the complications that this plan generates in the ``THE CHALLENGE" section.
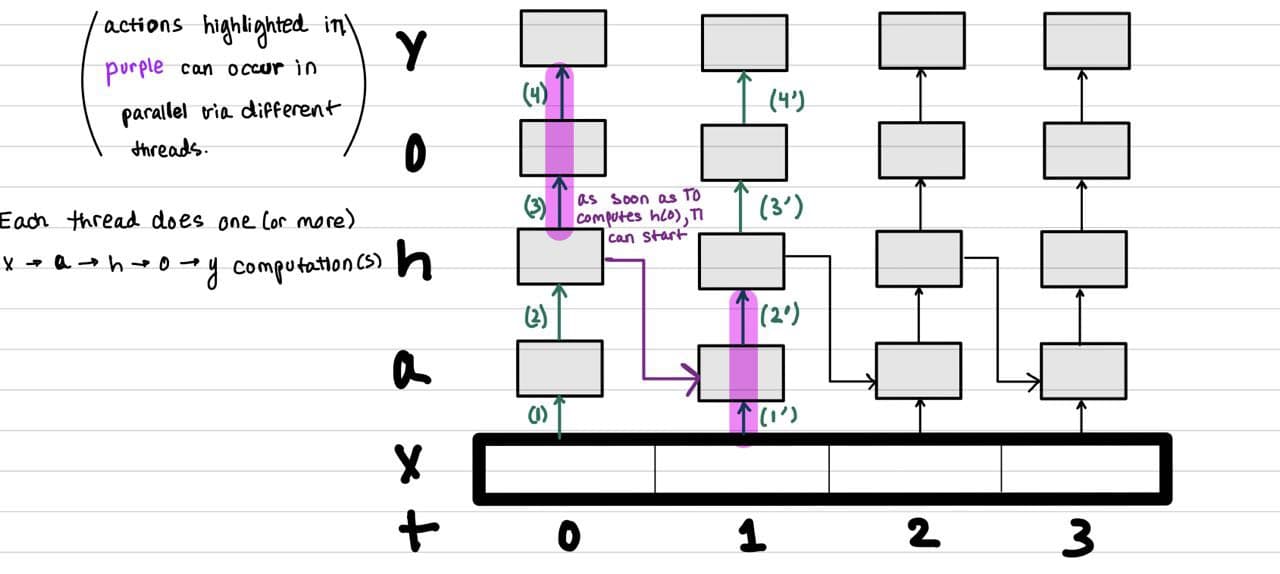
The following figure demonstrates the dependencies that this psudocode's computation entails:
⚙ The Challenge
RNNs' layers are composed neurons that have dependencies both on the outputs from ``below" layers and on outputs from previous time-steps, as illustrated in the BACKGROUND section. In the discussion from the previous section regarding forward passes for adjacent columns of neurons occurring on different processors, we alluded to the unavoidable necessity to communicate hidden-layer values. A salient topic to explore while implementing parallelization is whether this necessity is most efficiently met by using shared memory (which we will test using OpenMP), an orchestration of some form of point-to-point communication (we will test this as part of our additional goals, time permitting, with OpenMPI), and/or a tiering of caches that allows targeted memory-sharing among some processors.
⚙ Resources
We will need access to a computer with a NVIDIA GPU, in order to implement GPU-based accelerations (more detail on this appears in the ``PLATFORM CHOICE" section). Additionally, we will consult online resources that have psuedocode or python code for RNN inference computations (one such resource was already consulted in our discussion and is linked in-line). Additionally, we anticipate that we will consult online resources for CUDA programming, including formal developer guides published by NVIDIA.
⚙ Post-Milestone Schedule

PDF for Project Final Report
Final Project Slides
⚙ Summary
Our objective is to discover and exploit opportunities for parallelism in Recurrent Neural Networks' (RNNs') inference-time forward pass computations. We aim to effectively utilize synchronization and atomic operations to mitigate the purely-sequential nature to which the data dependencies within and across neural network layers lend themselves, so that we can use parallel computation APIs (e.g. openMP) and vectorized operations on GPUs for multiprocessor speedup.
⚙ Background
We are interested in finding effective ways to obtain speedup on the following basic algorithmic structure of a forward-pass computation in RNNs :
// x is a vector of inputs
a[t] = b + W * h[t-1] + U * x[t]
h[t] = tanh(a[t])
o[t] = c + V * h[t]
y[t] = softmax(o[t])
where the following variables correspond to layers that are vectors of neurons, indexed by time and ordered by increasing proximity to the output layer, y: a, h, o.
We plan to find some ways to mitigate the constraints enforced by dependent data: for example, the constraint on a[t] is the completion of the computation for the hidden layer's h's) output at time t-1. If different threads were responsible for the forward-pass computations of adjacent time steps, there would need to communication of hidden-layer values that would inhibit speedup. We elaborate more on the complications that this plan generates in the ``THE CHALLENGE" section.
The following figure demonstrates the dependencies that this psudocode's computation entails:
⚙ The Challenge
RNNs' layers are composed neurons that have dependencies both on the outputs from ``below" layers and on outputs from previous time-steps, as illustrated in the BACKGROUND section. In the discussion from the previous section regarding forward passes for adjacent columns of neurons occurring on different processors, we alluded to the unavoidable necessity to communicate hidden-layer values. A salient topic to explore while implementing parallelization is whether this necessity is most efficiently met by using shared memory (which we will test using OpenMP), an orchestration of some form of point-to-point communication (we will test this as part of our additional goals, time permitting, with OpenMPI), and/or a tiering of caches that allows targeted memory-sharing among some processors.
⚙ Resources
We will need access to a computer with a NVIDIA GPU, in order to implement GPU-based accelerations (more detail on this appears in the ``PLATFORM CHOICE" section). Additionally, we will consult online resources that have psuedocode or python code for RNN inference computations (one such resource was already consulted in our discussion and is linked in-line). Additionally, we anticipate that we will consult online resources for CUDA programming, including formal developer guides published by NVIDIA.
⚙ Post-Milestone Schedule
⚙ Summary
Our objective is to discover and exploit opportunities for parallelism in Recurrent Neural Networks' (RNNs') inference-time forward pass computations. We aim to effectively utilize synchronization and atomic operations to mitigate the purely-sequential nature to which the data dependencies within and across neural network layers lend themselves, so that we can use parallel computation APIs (e.g. openMP) and vectorized operations on GPUs for multiprocessor speedup.
⚙ Background
We are interested in finding effective ways to obtain speedup on the following basic algorithmic structure of a forward-pass computation in RNNs :
// x is a vector of inputs
a[t] = b + W * h[t-1] + U * x[t]
h[t] = tanh(a[t])
o[t] = c + V * h[t]
y[t] = softmax(o[t])
where the following variables correspond to layers that are vectors of neurons, indexed by time and ordered by increasing proximity to the output layer, y: a, h, o.
We plan to find some ways to mitigate the constraints enforced by dependent data: for example, the constraint on a[t] is the completion of the computation for the hidden layer's h's) output at time t-1. If different threads were responsible for the forward-pass computations of adjacent time steps, there would need to communication of hidden-layer values that would inhibit speedup. We elaborate more on the complications that this plan generates in the ``THE CHALLENGE" section. The following figure demonstrates the dependencies that this psudocode's computation entails:
⚙ The Challenge
RNNs' layers are composed neurons that have dependencies both on the outputs from ``below" layers and on outputs from previous time-steps, as illustrated in the BACKGROUND section. In the discussion from the previous section regarding forward passes for adjacent columns of neurons occurring on different processors, we alluded to the unavoidable necessity to communicate hidden-layer values. A salient topic to explore while implementing parallelization is whether this necessity is most efficiently met by using shared memory (which we will test using OpenMP), an orchestration of some form of point-to-point communication (we will test this as part of our additional goals, time permitting, with OpenMPI), and/or a tiering of caches that allows targeted memory-sharing among some processors.
⚙ Resources
We will need access to a computer with a NVIDIA GPU, in order to implement GPU-based accelerations (more detail on this appears in the ``PLATFORM CHOICE" section). Additionally, we will consult online resources that have psuedocode or python code for RNN inference computations (one such resource was already consulted in our discussion and is linked in-line). Additionally, we anticipate that we will consult online resources for CUDA programming, including formal developer guides published by NVIDIA.
⚙ Post-Milestone Schedule